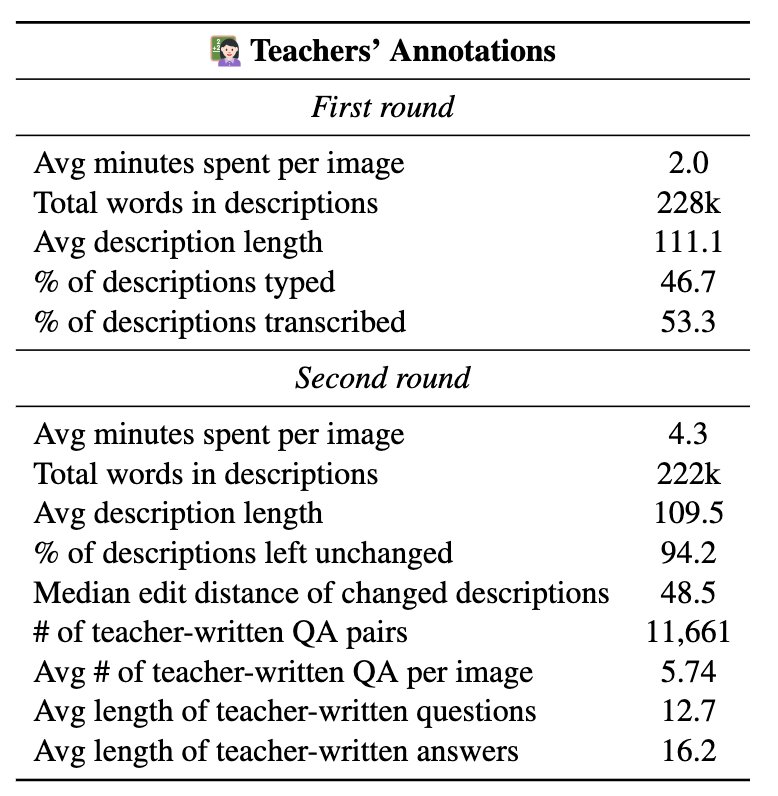
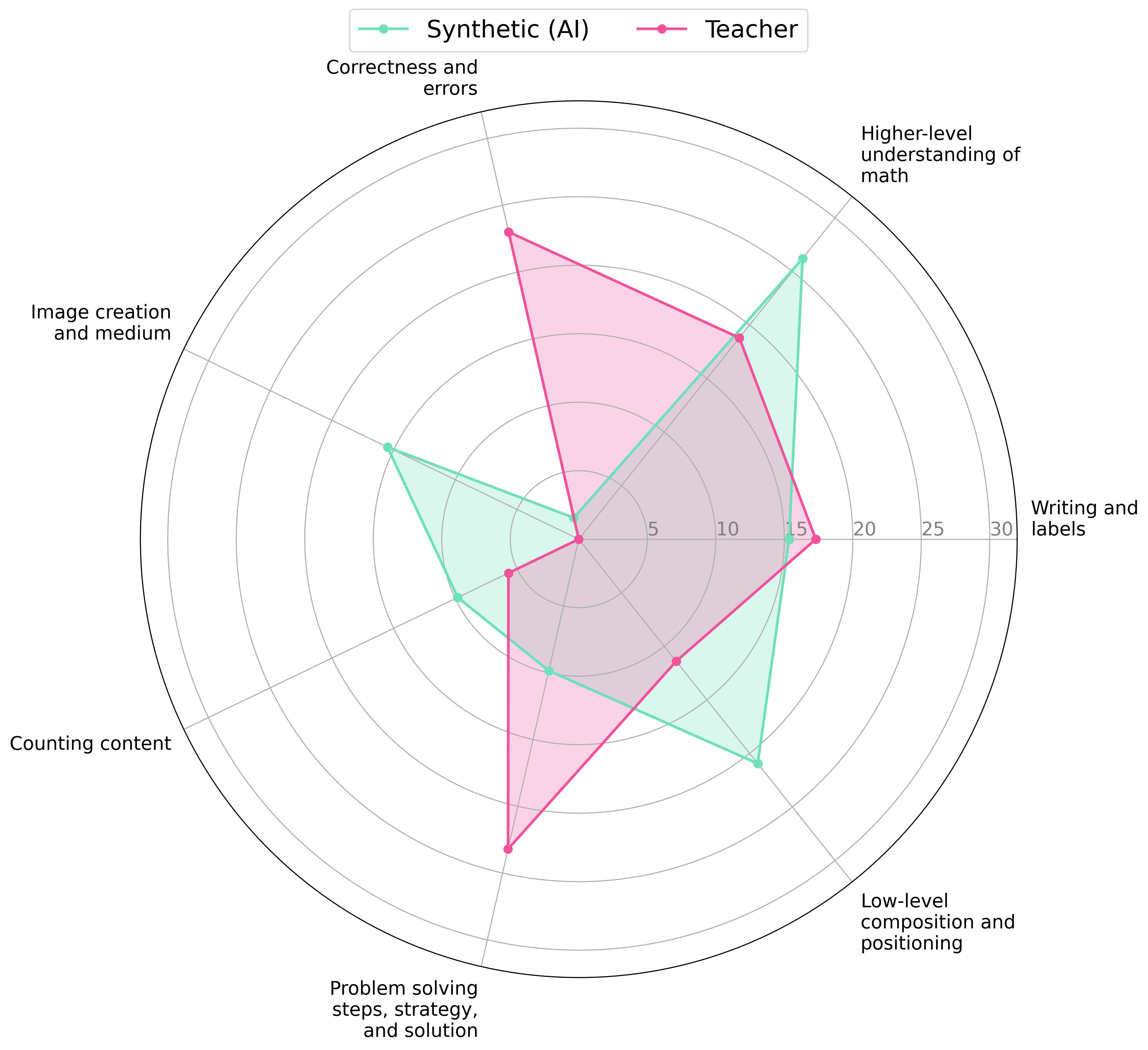
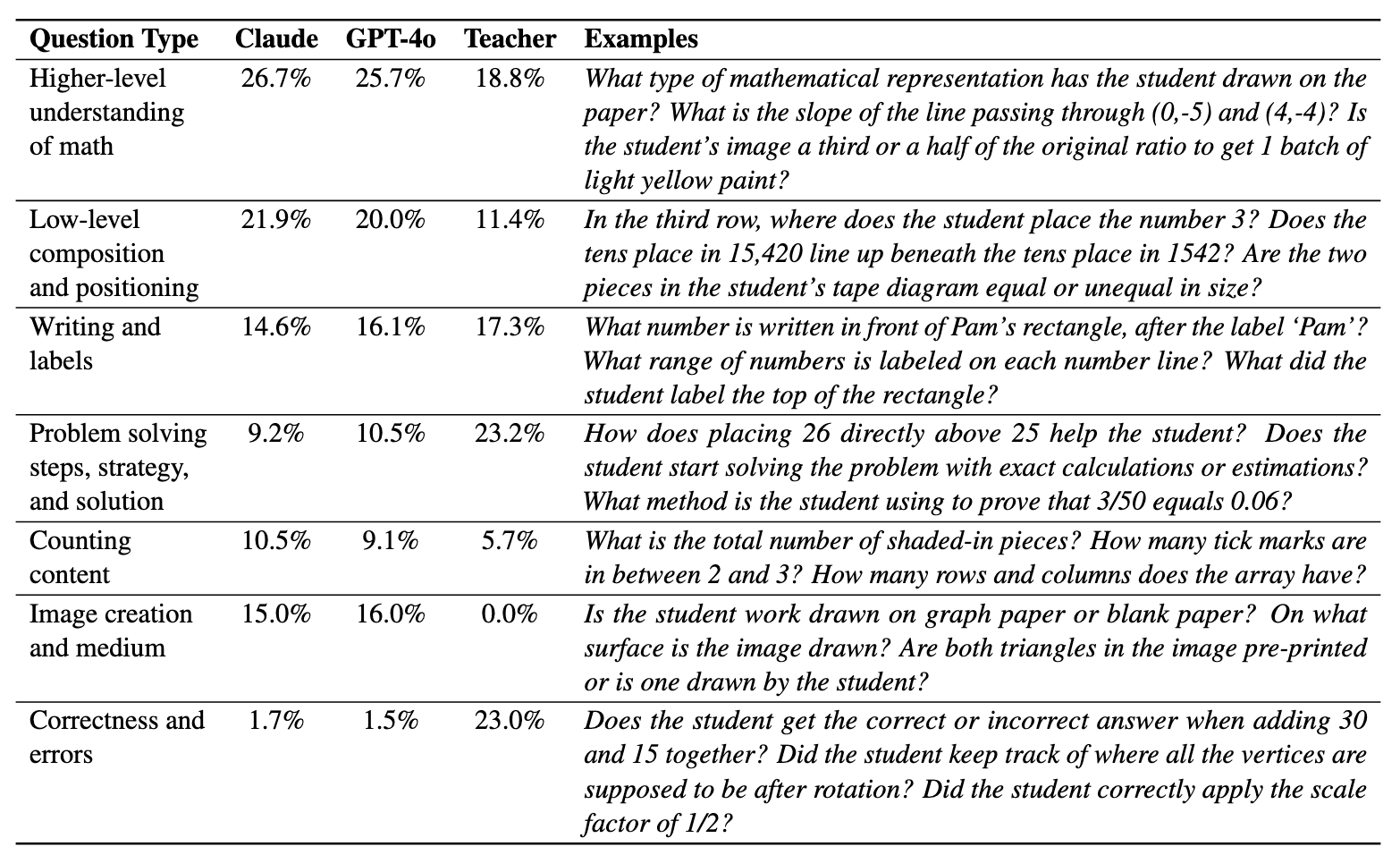
Accuracy scores on the
![]() DrawEduMath dataset.
DrawEduMath dataset.
| # | Model | Date | Teacher QA | Synthetic QA |
| 1 | Gemini 3 Pro Preview | 2025-12-23 | 0.713 | - |
| 2 | Gemini 2.5 Pro Preview | 2025-04-07 | 0.660 | 0.789 |
| 3 | GPT 5 | 2025-11-01 | 0.640 | 0.796 |
| 4 | Gemini 2.5 Pro | 2025-10-27 | 0.635 | 0.780 |
| 5 | GPT 4.5 Preview | 2025-04-04 | 0.592 | 0.765 |
| 6 | GPT 4.1 | 2025-04-19 | 0.581 | 0.743 |
| 7 | Claude Opus 4.5 | 2025-12-23 | 0.578 | - |
| 8 | GPT o4-mini | 2025-04-18 | 0.572 | 0.757 |
| 9 | GPT 5.2 | 2025-12-23 | 0.564 | - |
| 10 | Gemini Flash 2.0 | 2025-03-11 | 0.545 | 0.704 |
| 11 | Claude 3.7 Sonnet | 2025-03-05 | 0.517 | 0.673 |
| 12 | Claude Sonnet 4 | 2025-11-15 | 0.476 | 0.690 |
| 13 | Claude Sonnet 4.5 | 2025-12-05 | 0.473 | 0.689 |
| 14 | Llama 4 Scout | 2025-04-18 | 0.445 | 0.610 |
The leaderboard scores are based on binarized accuracy (correct/incorrect) of VLM responses as judged by an ensemble of three models (Claude 3.5 Sonnet, Gemini 2.5 Pro, and GPT-4o), with the final rating determined by the mode across judges.
🚨 To submit your results to the leaderboard, please send to this email with your result json files.